What is activation function ?
Activation function is the most important piece in neural networks. Activation function is used in every layer except in input layer. The different layers can have different activation functions. Each neuron has an activation function which takes the input (weighted sum) and applies some transformations to produce output. It is an element-wise function and doesn't change the shape of input. Activation function should be differential in order to perform back-propagation.

Why activation function ?
The main use of activation function is to introduce non-linearity in the network. Otherwise, how large the network may be, the output will be the linear combination of inputs. Neural networks can approximate any function. That's why they neural networks be used to solve any real world problems when problem is formulated as the function.
Activation function in hidden layer
Activation function in the hidden layers play the vital role in training neural networks. They determine how fast the neural network converges and whether it is capable of solving desired problem. ReLU activation function is mostly used in hidden layers. It is not perfect but a very good default activation function. It is fast to compute and doesn't saturate for positive values.
Activation function in output layer
In output layer, sigmoid activation function is used for binary classification task and softmax activation function is used for multi-class classification task. For regression tasks, no activation function is used at all. Use of activation function in the output layer totally depends on the desired output of the network.
Popular Activation Functions
There are various activation functions which have their own benefits and drawbacks. Lets have a look at few widely used activation functions. All varaints of ReLUs and ELU are used in hidden layers.
Sigmoid/Logistic Activation Function:
It takes input and outputs a value in the range: (0, 1). It is mostly used at the output layer. It is useful when the problem is binary classification or any regression task that requires output value between 0 and 1.
 Softmax Activation Function:
Softmax Activation Function:
Its same as sigmoid activation function but it can be used for multi-class classification (mutually exclusive classes).
i.e. output layer can have two or more neurons and sum of all neurons output equals to 1.
Hyperbolic Tangent Function (tanh):
This function takes input and outputs a value in the range: (-1, 1). It is also used in output layer.
 Rectified Linear Unit (ReLU):
Rectified Linear Unit (ReLU):
Its simple, yet powerful activation function. It takes input and outputs a value in the range: max(0, x) i.e. ReLU(x) = max(0, x). It is widely hidden layer activation function in various neural network architecture.
 Leaky ReLU Activation Function:
Leaky ReLU Activation Function:
It is derived version of ReLU which solves the demerit of standard ReLU. The demerit is that standard ReLU can't handle vanishing gradient problem (also known as dying ReLU). When the weighted sum of inputs to neuron is negative, it always outputs zero.
Leaky ReLU activation function is defined as: LeakyReLU(x) = max(𝛼x, x), where 𝛼 is generally set to 0.01.
There are other two variants of Leaky ReLU:
*Variants of leaky ReLU seem to outperform standard ReLU on large datasets but they have risk of overfitting on small datasets.
Exponential Linear unit (ELU):
It outperforms all the ReLU variants. With less training time than ReLU, neural network gives the better results on test set. ELU is slower to compute than ReLUs (due to the use of the exponential function) but has faster convergence rate. ELU is a good default if the prediction time doesn't matter a lot.

In summary,
ELU > leaky ReLU (and its variants) > ReLU > tanh > logistic.
Activation function is the most important piece in neural networks. Activation function is used in every layer except in input layer. The different layers can have different activation functions. Each neuron has an activation function which takes the input (weighted sum) and applies some transformations to produce output. It is an element-wise function and doesn't change the shape of input. Activation function should be differential in order to perform back-propagation.

Why activation function ?
The main use of activation function is to introduce non-linearity in the network. Otherwise, how large the network may be, the output will be the linear combination of inputs. Neural networks can approximate any function. That's why they neural networks be used to solve any real world problems when problem is formulated as the function.
Activation function in hidden layer
Activation function in the hidden layers play the vital role in training neural networks. They determine how fast the neural network converges and whether it is capable of solving desired problem. ReLU activation function is mostly used in hidden layers. It is not perfect but a very good default activation function. It is fast to compute and doesn't saturate for positive values.
Activation function in output layer
In output layer, sigmoid activation function is used for binary classification task and softmax activation function is used for multi-class classification task. For regression tasks, no activation function is used at all. Use of activation function in the output layer totally depends on the desired output of the network.
Popular Activation Functions
There are various activation functions which have their own benefits and drawbacks. Lets have a look at few widely used activation functions. All varaints of ReLUs and ELU are used in hidden layers.
Sigmoid/Logistic Activation Function:
It takes input and outputs a value in the range: (0, 1). It is mostly used at the output layer. It is useful when the problem is binary classification or any regression task that requires output value between 0 and 1.

Its same as sigmoid activation function but it can be used for multi-class classification (mutually exclusive classes).
i.e. output layer can have two or more neurons and sum of all neurons output equals to 1.
Hyperbolic Tangent Function (tanh):
This function takes input and outputs a value in the range: (-1, 1). It is also used in output layer.

Its simple, yet powerful activation function. It takes input and outputs a value in the range: max(0, x) i.e. ReLU(x) = max(0, x). It is widely hidden layer activation function in various neural network architecture.
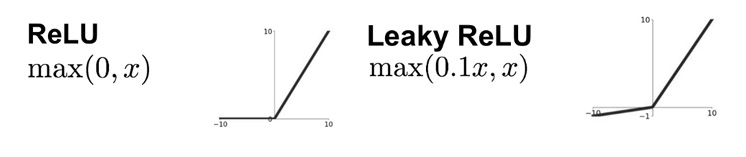
It is derived version of ReLU which solves the demerit of standard ReLU. The demerit is that standard ReLU can't handle vanishing gradient problem (also known as dying ReLU). When the weighted sum of inputs to neuron is negative, it always outputs zero.
Leaky ReLU activation function is defined as: LeakyReLU(x) = max(𝛼x, x), where 𝛼 is generally set to 0.01.
There are other two variants of Leaky ReLU:
- Randomized Leaky ReLU (RReLU): 𝛼 is picked randomly from a given range during training and fixed to an average value during testing.
- Parametric Leaky ReLU (PReLU): α is learned during training. Instead of being a hyperparameter, it is learned by backpropagation like any other parameter.
*Variants of leaky ReLU seem to outperform standard ReLU on large datasets but they have risk of overfitting on small datasets.
Exponential Linear unit (ELU):
It outperforms all the ReLU variants. With less training time than ReLU, neural network gives the better results on test set. ELU is slower to compute than ReLUs (due to the use of the exponential function) but has faster convergence rate. ELU is a good default if the prediction time doesn't matter a lot.

Which is the best activation function for hidden layers ?
It is quite easy to choose activation function for output layer of neural network. The main problem is to choose the best activation function to be used in the hidden layers. Activation function used in the hidden layer makes a huge impact on training neural network. ReLU works best in all cases.In summary,
ELU > leaky ReLU (and its variants) > ReLU > tanh > logistic.
Comments
Post a Comment